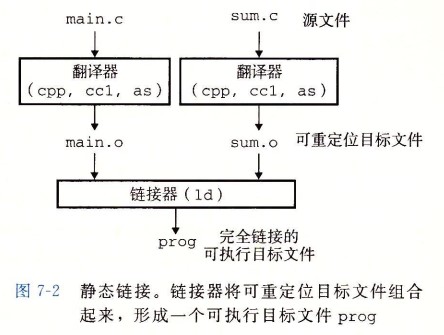
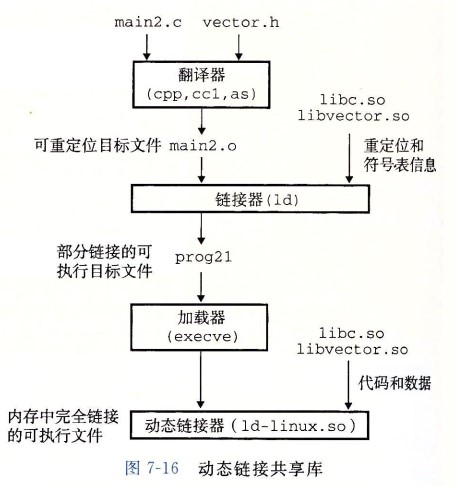
以太网
以太网是一种计算机局域网技术。IEEE组织的IEEE 802.3标准制定了以太网的技术标准,它规定了包括物理层的连线、电子信号和介质访问层协议的内容。以太网是目前应用最普遍的局域网技术。
以太网有两类:第一类是经典以太网,第二类是交换式以太网,使用了一种称为交换机的设备连接不同的计算机。经典以太网是以太网的原始形式,运行速度从3~10 Mbps不等;而交换式以太网正是广泛应用的以太网,可运行在100、1000和10000Mbps那样的高速率,分别以快速以太网、千兆以太网和万兆以太网的形式呈现。
互联网是网络的网络
网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。互联网(Internet)是全球范围的互连网。
ISP(网络服务提供商)
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
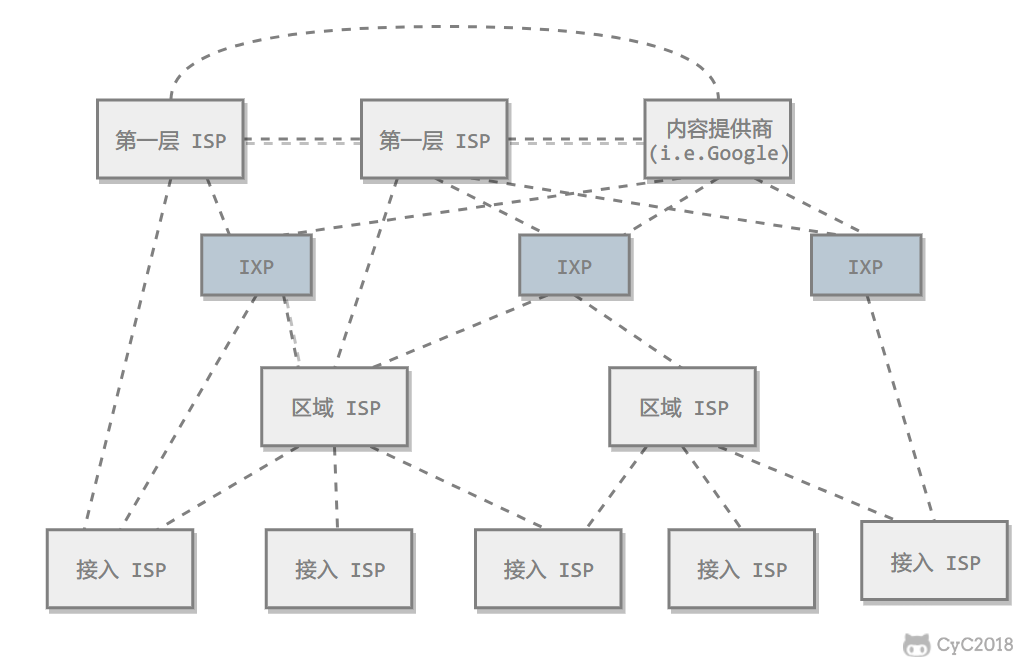
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP(互联网交换中心,功能相当于计算机网络中所提及的交换机) 允许两个 ISP 直接相连而不用经过第三个 ISP。
主机之间的通信方式
- 客户-服务器(C(client)/S(server)):客户是服务的请求方,服务器是服务的提供方。
- 对等(P2P):不区分客户和服务器。
分组
分组是将一个数据包分成一个个更小的数据包的操作。
交换
简单地讲,就是服务器与服务器之间的数据交换。
电路交换、报文交换和分组交换

电路交换:电路交换用于电话通信系统,两个用户要通信之前需要建立一条专用的物理链路,并且在整个通信过程中始终占用该链路。由于通信的过程中不可能一直在使用传输线路,因此电路交换对线路的利用率很低,往往不到 10%。电路交换的三个阶段:1.建立连接,2.数据传输,3.释放连接
报文交换(不常用):整个报文先传输到相邻的结点,全部存储下来后查找转发表,转发到下一个结点。
分组交换:单个分组(报文的一部分)传送到相邻结点,相邻结点存储下来后查找转发表,转发到下一个结点,即是一种采取把小数据包存储转发传输的机制。每个分组都有首部和尾部,包含了源地址和目的地址等控制信息,在同一个传输线路上同时传输多个分组互相不会影响,因此在同一条传输线路上允许同时传输多个分组,也就是说分组交换不需要占用传输线路。类比于邮局通信系统,邮局收到一份邮件之后,先存储下来,然后把相同目的地的邮件一起转发到下一个目的地,这个过程就是存储转发过程,分组交换也使用了存储转发过程。
速率
指的是单位时间传送的比特数,其单位是 b/s(比特每秒)。一个比特(bit)就是一个二进制数字中的一个 1 或 0。
带宽
在计算机网络中,带宽用来表示通信线路的数据传输能力,因此网络带宽指的是在单位时间内从网络中的某一点到另一点所能通过的最高速率。
时延
时延指的是数据从网络的一端传送到另一端所需的时间。
总时延 = 排队时延 + 处理时延 + 传输时延(发送时延)+ 传播时延
排队时延:分组在进入路由器后要先在输入队列中等待处理。在路由器确定了转发接口后还需要在输出队列中等待转发,所以就产生了排队时延。分组在路由器的输入队列和输出队列中排队等待的时间,取决于网络当前的通信量。
处理时延:主机或者路由器在接受到分组时候要花费一定的时间进行处理,例如分析分组的首部,从分组中提取数据部分,运行差错检验或是查找适当的路由等等。
传输时延(发送时延):主机或者路由器发送数据帧所需要的时间。

传播时延:电磁波在信道中传播一定距离需要花费的时间

计算机网络体系结构
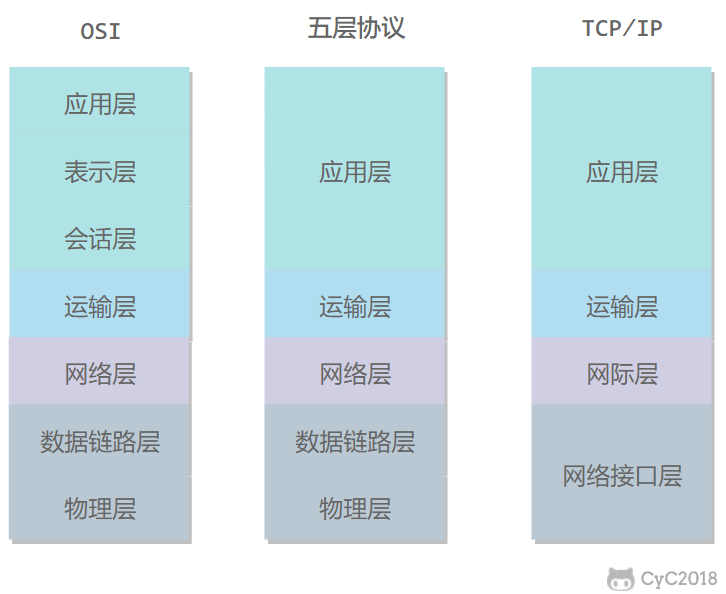
1. 五层协议:
应用层:为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
传输层:为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
网络层:为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
数据链路层:网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
物理层:考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
2. OSI七层模型
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
3. TCP/IP
它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
数据在各层之间的传递过程
在向下层传递的过程中,需要添加下层协议所需要的首部或者尾部,而在向上的过程中不断拆开首部和尾部。
路由器只有下面三层协议,因为路由器位于网络核心中,不需要为进程或者应用程序提供服务,因此也就不需要传输层和应用层。
参考资料
CS-Notes
电路交换,报文交换,分组交换